研究所动态
喜报 | 我所两篇论文被人工智能顶级会议AAAI 2024录用
发布时间:2023年12月11日
近日,人工智能国际会议AAAI 2024公布录用结果,由我所师生共同完成的2篇论文被大会录用。 AAAI是CCF推荐的A类国际学术会议。本次AAAI 2024一共有9862篇投稿,录用2342篇,录用率23.75%。此次我所被录用的论文的相关信息如下:
论文一
What Effects the Generalization in Visual Reinforcement Learning: Policy Consistency with Truncated Return Prediction
该论文由我所博士生王硕、胡小波和王金文在吕凯、武志昊和林友芳老师的指导下完成。
在视觉强化学习(RL)中,泛化到新环境的挑战至关重要。这项研究对视觉强化学习泛化进行了理论分析,建立了泛化目标的上限,包括策略分歧和贝尔曼误差分量。受此分析的启发,我们建议保持策略空间中多个策略的跨域一致性,来减少测试期间学习策略的分歧。 在实践中,我们引入了截断回报预测(TRP)任务,通过预测历史轨迹的截断回报来促进跨域策略的一致性。此外,我们还为该辅助任务提出了一个基于 Transformer 的预测器。 三个仿真环境上多个任务的实验结果证明了所提出方法的优越性。

论文二
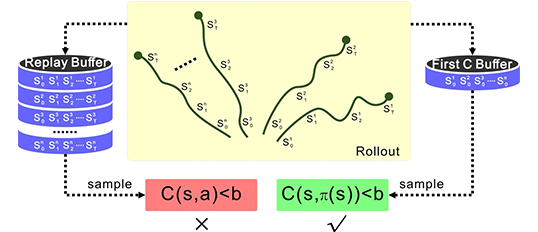
Enhancing Off-policy Constrained Reinforcement Learning through Adaptive Ensemble C Estimation
论文由我所博士生张恒瑞和毕业生沈硕(腾讯)在林友芳老师,韩升老师,吕凯老师的指导下完成。
在现实世界的智能体领域,由于安全约束的必要性,强化学习的应用具有挑战性。此前,约束强化学习主要关注on-policy算法。尽管这些算法表现出一定程度的有效性,但它们在现实世界设置中的交互效率并不是最优的,这凸显了对更高效的off-policy方法的需求。然而,off-policy策略 CRL 算法在精确估计 C 函数方面面临着挑战,特别是由于受限拉格朗日乘数的波动。为了解决这一差距,我们的研究重点关注off-policy CRL 中 C 值估计的细微差别,并引入自适应集成 C 学习 (AEC) 方法来减少这些不准确性。基于最先进的off-policy算法SAC和TQC,我们提出了基于 AEC 的 CRL 算法AECSAC和AECTQC,旨在增强任务优化。对九个安全约束机器人任务的大量实验表明,与之前的方法相比,我们的算法具有卓越的交互效率和性能
恭喜以上老师和同学在科研中取得优秀的成果,也希望同学们能够再接再厉,继续在科研的道路上不断前行,取得更多优异的成果。