研究所动态
喜报 | 我所一篇论文被国际顶级会议IJCAI 2024录用
发布时间:2024年04月18日
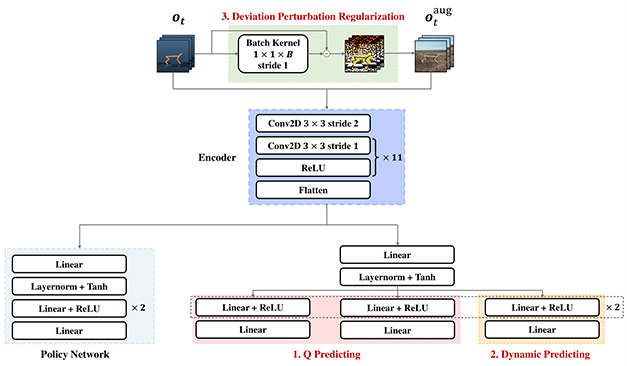
由我所师生合作完成的一篇论文How to Learn Domain-Invariant Representations for Visual Reinforcement Learning: An Information-Theoretical Perspective被国际顶级会议33rd International Joint Conference on Artificial Intelligence (IJCAI’24)录用,该论文由我所博士生王硕、王金文、胡小波,在武志昊老师、林友芳老师、吕凯老师的指导下完成。
尽管在视觉控制挑战方面取得了令人印象深刻的成功,但视觉强化学习(VRL)策略仍难以推广到其他场景。 现有的工作经验性地提高了泛化能力,但缺乏理论支持。 在这项工作中,我们探索如何从信息理论的角度学习 VRL 的域不变表示。 具体来说,我们确定了三个互信息 (MI) 项。 这些项强调了,鲁棒的表示应该在显著的观测扰动下保留域不变信息(累计奖励和环境转移)。 此外,我们缩放了 MI 项,推导出了三个组件,用于实践VRL 的基于互信息的不变表示 (MIIR) 算法。 大量实验表明,MIIR 在 DeepMind 控制套件、机器人操作和 Carla 中实现了最先进的泛化性能和最佳样本效率。