研究所动态
喜报 | 我所三篇论文被国际顶级会议ACM MM2025录用
发布时间:2025年7月9日
近日,多媒体技术国际顶级会议ACMMM 2025公布录用结果,由我所师生共同完成的3篇论文被大会录用。ACM International Conference on Multimedia (ACM MM)是中国计算机学会(CCF)推荐的A类国际学术会议。ACM MM 2025共有4672份有效投稿,录用1251篇,录用率为26%,此次我所被录用的论文的相关信息如下:
论文一
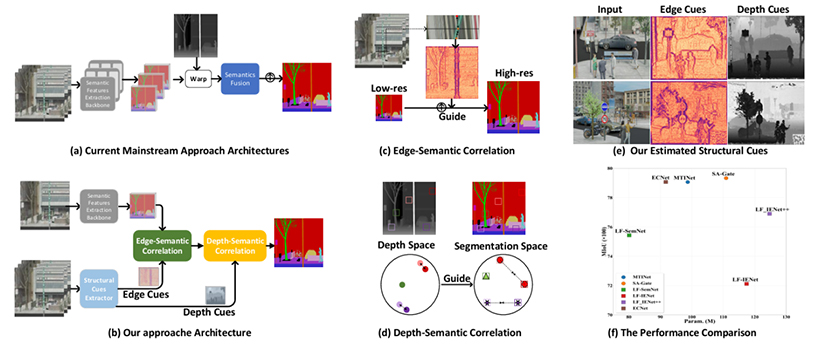
Epipolar Consistency-based Network for Structure-Aware LF Semantic Segmentation
该论文由我所博士生高晨、硕士生王文彬在张硕老师和林友芳老师的指导下完成
光场语义分割旨在充分利用跨视角捕获的冗余信息,为中心视角中的每个像素分配精确的语义标签。现有主流方法通常将多个视图分别输入预训练的语义分割网络,并依赖估计的深度图来聚合多视角语义特征以细化标签预测。然而,这些方法存在两方面局限:一方面,语义分割网络往往更关注高层语义特征,忽略了细节信息,导致预测边界模糊、精度下降;另一方面,光场中记录的多视角语义特征存在高度冗余,直接融合不仅增加了无效计算,也带来了资源浪费。为解决上述问题,我们提出了一种基于极线一致性的结构感知光场语义分割网络,探索光场中结构线索与语义标签之间的相关性。首先,我们利用视图间的极线一致性来提取遮挡边缘和深度线索,作为指导信息。基于嵌入的遮挡边缘特征,我们设计了边缘-语义关联 Transformer,用于生成物体边缘的细粒度表示;同时,提出的深度-语义关联 Transformer 能将语义特征更紧密地映射到空间上相邻的位置,从而增强空间一致性与结构感知能力。实验结果表明,所提出的方法在显著降低计算复杂度的同时,能够实现最先进的分割性能,特别在细节还原和边界准确性方面表现出明显优势。
论文二
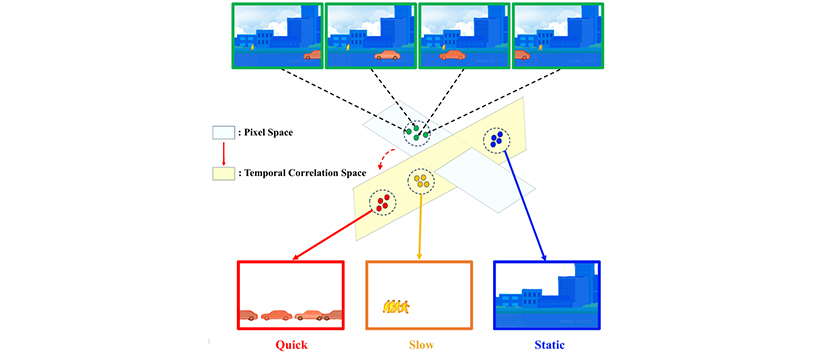
From Pixels to Temporal Correlations: Learning Informative Representations for Reinforcement Learning Pre-training
该论文由我所博士生王金文、胡小波、硕士生杨思语在林友芳老师、韩升老师、王硕老师和吕凯老师的指导下完成。
在大规模数据集上进行无监督预训练已被证明在提升强化学习 (RL) 的样本效率和性能方面具有巨大潜力。针对大规模无动作网络视频,现有方法利用单步转移预测和图像重建来学习表征。然而,这些方法倾向于在像素空间中保留大像素比例的平稳信息,而忽略了小占比但至关重要的信息。为了在表征中保留足够的信息,必须对视频中的每个元素给予同等的关注。具体而言,我们提出了一个时间相关性空间来区分每个元素。在实现上,我们设计了一组对比学习目标,分别对每个时间相关性尺度进行独立建模。这种方法可以平衡不同元素的注意力,并产生更具信息量的表征,从而有效地支持各种下游任务中的策略学习。在三个不同的下游基准(DMControl Remastered、Meta-World 和 CARLA)上进行了广泛的实验,证明了我们的方法显著提高了各种下游任务的样本效率和渐进性能。
论文三
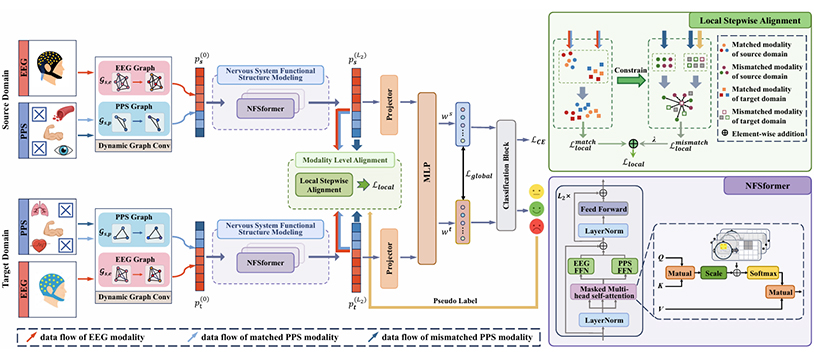
MoCERNet: A Modality-Complete Modeling Framework for Emotion Recognition in Physiological Signals under Imperfect Modal Matching
该论文由我所硕士生辛天佐、博士生靳希源、宁晓军、硕士生冯志洋在王晶老师和林友芳老师的指导下完成。
基于多模态生理信号的情感识别在人机交互、疾病诊断等领域扮演着日益重要的角色,其可以很好地模拟人类情绪的复杂生理过程,且不易受到主观偏见或故意欺骗的影响,在情感计算研究中得到了广泛应用。然而,当前研究主要是在统一的数据采集范式下进行,忽视了现实场景中普遍存在的模态不完美匹配问题。尤其值得注意的是,现有方法未能有效利用这些不匹配模态,导致情绪表征不完整,这限制了模型准确捕捉多维情感语义特征的能力,进而制约了其在实际场景中的有效性和适用性。同时,现有方法忽略了不同脑区和外周生理信号间有价值的局部功能结构。针对上述挑战,本研究提出了一种名为MoCERNet的模型:采用多级分步对齐策略,使目标域和源域互相适应不匹配的模态范式组合,首先在模态层面缩小匹配模态间的差距,随后以匹配模态为指导,通过语义感知方式对齐不匹配模态;在决策层面,进一步消除全局差异以获得完整且具有泛化能力的表征。此外,我们设计了神经系统功能结构Transformer(NFSformer)使模型能聚焦于不同情绪状态下大脑各区域与外周生理信号间的关联性,从而增强其对复杂情绪过程的建模能力。在三个数据集上的结果表明,MoCERNet优于多个基准模型。我们希望我们的工作可以拓宽基于生理信号的情感识别模型的应用场景,并促进情感识别模型的未来发展和推广。
恭喜以上老师和同学在科研中取得优秀的成果,也希望同学们能够再接再厉,继续在科研的道路上不断前行,取得更多优异的成果。