研究所动态
研究所2025年上半年25篇CCF-A类学术论文成果速览
发布时间:2025年7月11日
2025年1月至6月,北京交通大学网络科学与智能系统研究所师生在CCF-A类国际期刊和会议共录用及发表学术论文25篇,其中CCF-A类会议论文18篇(AAAI 6篇,IJCAI 3篇,ACM MM 3篇,ICCV 2篇,KDD、ICML、ICLR 、ACL各1篇),CCF-A类期刊论文7篇(TKDE4篇, TVCG、TSE、TMC各1篇)。研究成果涵盖时空数据挖掘及其在交通和物流等领域的应用、时序数据挖掘与应用、时空知识图谱、交通目标检测、光场图像处理、多智能体、深度强化学习及应用、交通信号控制、软件工程等研究方向。论文的相关信息如下:
论文1
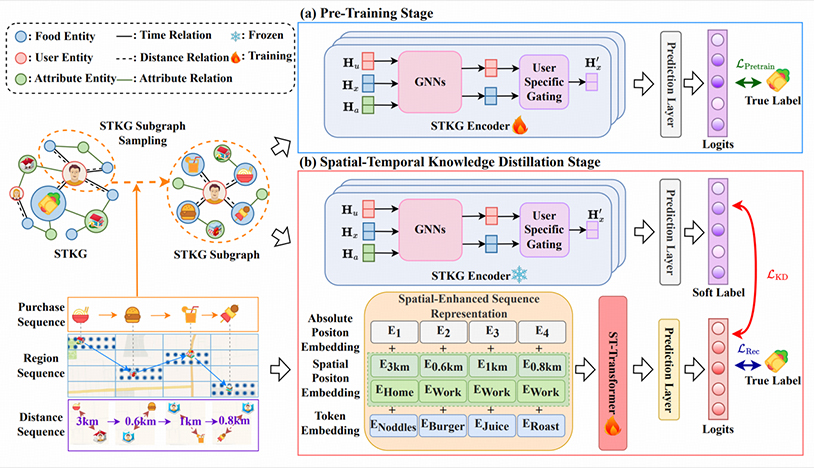
Spatial-Temporal Knowledge Distillation for Takeaway Recommendation
录用\发表平台:AAAI 2025
作者:Shuyuan Zhao, Wei Chen, Boyan Shi, Liyong Zhou, Shuohao Lin, Huaiyu Wan
论文简介:
外卖推荐系统旨在根据用户的历史购买序列来为用户推荐未来可能购买的外卖选项,从而提升用户的满意度并促进商家的销售。现有方法主要聚焦于整合辅助信息(如地理空间数据)或利用知识图谱(KGs)来缓解序列数据的稀疏性问题。然而,这些方法在性能上主要受到两个挑战的限制:(1)捕捉用户基于复杂地理空间信息的动态偏好;(2)以低计算成本高效地整合图结构数据与序列数据中的时空知识。在本文中,我们提出了一种新颖的、基于两阶段训练过程的时空知识蒸馏外卖推荐模型(STKDRec)。具体而言,在第一阶段的预训练中,我们训练一个时空知识图谱(STKG)编码器,以从STKG中提取高阶时空依赖关系和协同关联。在第二阶段的时空知识蒸馏(STKD)中,我们采用一个时空Transformer(ST-Transformer)从序列角度全面建模用户基于多种地理空间信息的动态偏好。此外,我们还引入了STKD策略,将基于图的时空知识迁移到ST-Transformer中,这既促进了来自STKG和序列数据的丰富知识的自适应融合,又降低了计算开销。在三个真实世界数据集上进行的大量实验表明,STKDRec的性能显著优于当前最先进的基线模型。
论文网址: https://arxiv.org/abs/2412.16502
代码网址: https://github.com/Zhaoshuyuan0246/STKDRec
论文2
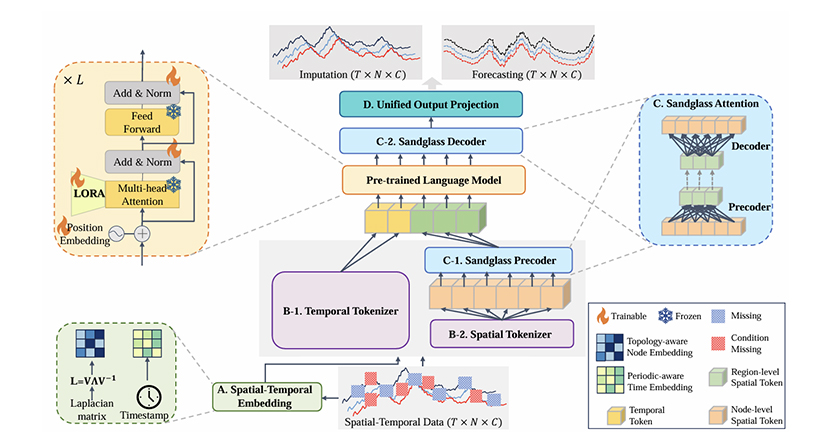
STD-PLM: Understanding Both Spatial and Temporal Properties of Spatial-Temporal Data with PLM
录用\发表平台:AAAI 2025
作者:YiHeng Huang, Xiaowei Mao, Shengnan Guo, Yubin Chen, Junfeng Shen, Tiankuo Li, Youfang Lin, Huaiyu Wan
论文简介:
时空预测和插补对于智能交通系统的发展非常重要。然而大多数现有方法都是针对单个预测或插补任务设计的,无法同时适用于两者,这增加了模型训练部署的成本。此外,现有时空模型的零样本和少样本学习学习能力较差。虽然预训练语言模型 (PLM) 在各种任务(包括少样本和零样本学习)上表现出强大的模式识别和推理能力,但由于对时间相关性、空间连通性、非点对和高阶时空相关性等复杂的时空关系建模不足的限制,它们无法直接应用于时空任务上。 在本文中,我们提出了 STD-PLM,使PLM能够理解时空数据的空间和时间属性并同时实现时空预测和插补任务。STD-PLM 通过精心设计的时空Tokenizer来理解时空相关性。并引入拓扑感知节点嵌入,让 PLM 以归纳方式理解和利用数据的拓扑结构。此外,为了缓解 PLM 引入的效率问题,我们设计了一个沙漏注意模块 (SGA),结合特定的约束损失函数,在确保性能的同时显著提高了模型的效率。 实验表明,STD-PLM 在各种数据集的预测、插补任务、少样本以及零样本任务中表现出了卓越的性能和泛化能力。
论文网址: https://arxiv.org/abs/2407.09096
代码网址: https://github.com/Hyheng/STD-PLM
论文3
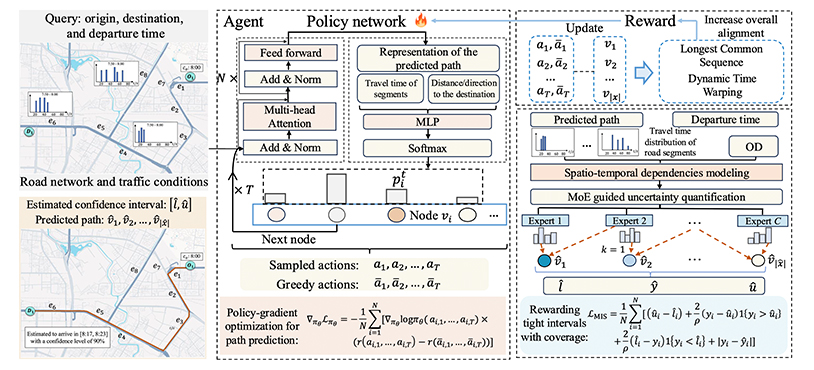
DutyTTE: Deciphering Uncertainty in Origin-Destination Travel Time Estimation
录用\发表平台:AAAI 2025
作者:Xiaowei Mao, Yan Lin, Shengnan Guo, Yubin Chen, Xingyu Xian, Haomin Wen, Qisen Xu, Youfang Lin, Huaiyu Wan
论文简介:
量化起终点行程时间不确定性的目标是基于起点、终点和出发时间估计行程时间的置信区间。准确量化这种不确定性需要生成最可能的路径,并评估路径上每个路段的通行时间不确定性。这主要涉及两个挑战:1)预测与真实路径一致的路径;2)在变化交通状况下建模每个路段的通行时间对总行程时间不确定性的影响。为了解决这些挑战,我们提出了DutyTTE方法。针对第一个挑战,我们引入了一种深度强化学习方法,以提高预测路径与真实路径的一致性,缓解路径预测中的误差累积,从而更准确地获取经过路段的行程时间信息,以提升行程时间估计的准确性。针对第二个挑战,我们提出了一种由混合专家网络引导的不确定性量化机制,以更好地捕获每个路段在不同行程和交通状况下的通行时间不确定性。此外,我们基于Hoeffding置信上界对结果进行校准,从统计意义上保证估计的置信区间符合预期。在多个数据集上的大量实验表明,本文提出的方法优于基准方法,准确地量化了起终点行程时间的不确定性。
论文网址: https://arxiv.org/abs/2408.12809
代码网址: https://github.com/maoxiaowei97/DutyTTE
论文4
CognTKE: A Cognitive Temporal Knowledge Extrapolation Framework
录用\发表平台:AAAI 2025
作者:Wei Chen, Yuting Wu, Shuhan Wu, Zhiyu Zhang, Mengqi Liao, Youfang Lin, Huaiyu Wan
论文简介:
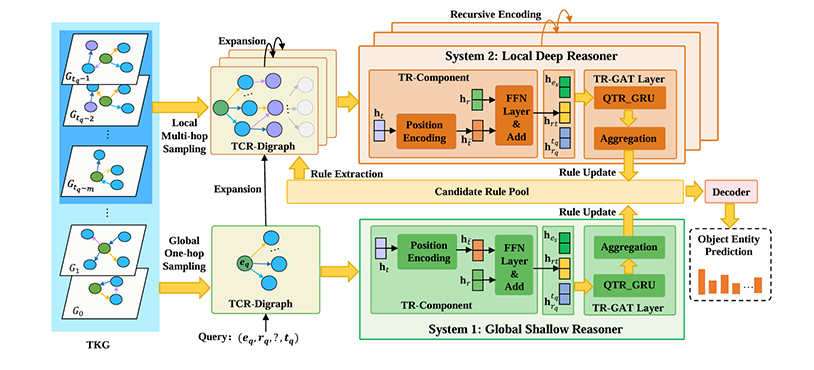
时序知识图谱(TKGs)外推旨在根据历史的事实来预测未来可能发生的事实。现有的可解释推理研究主要集中在对与查询相关的可理解的时序路径进行建模。然而,这些基于路径的方法主要关注近期出现的局部时间路径,无法捕捉到 TKG 中复杂的时间路径,从而导致与查询相关的更长的历史关系丢失。受认知科学中双重过程理论的启发,本文提出了一个认知时序知识外推框架(CognTKE),该框架引入了一种新的时序认知关系有向图(TCR-Digraph),并在 TCR-Digraph 上执行可解释的全局浅层推理和局部深层推理。具体而言,TCR-Digraph 通过检索与查询相关的显著局部和全局历史时间关系路径来构成,然后,CognTKE 分别提出了全局浅层推理器和局部深层推理器,在TCR-Digraph上执行全局单跳时序关系推理和局部复杂多跳路径推理。在四个基准数据集上的实验结果表明,与最先进的基线相比,CognTKE 在准确性方面取得了显著的提升,并展现出出色的零样本推理能力。
论文网址: https://arxiv.org/pdf/2412.16557
代码网址: https://github.com/WeiChen3690/CognTKE
论文5
Infer the Whole from a Glimpse of a Part: Keypoint-based Knowledge Graph for Vehicle Re-identification
录用\发表平台:AAAI 2025
作者:Kai Lv, Yunlong Li, Zhuo Chen, Shuo Wang, Sheng Han, Youfang Lin
论文简介:
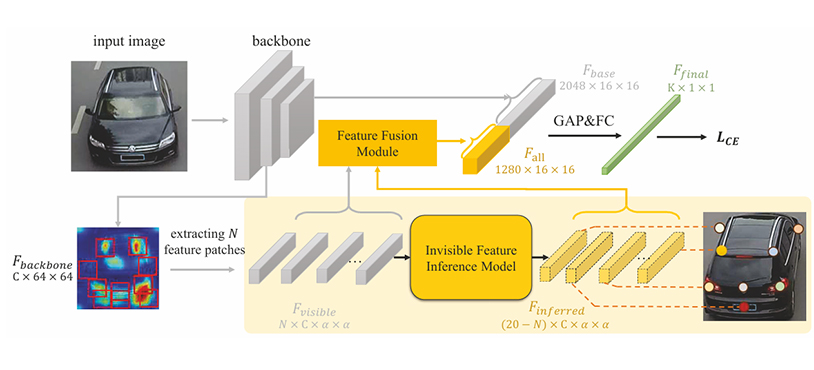
本文提出了一种基于关键点知识图的车辆重识别新方法,旨在解决跨非重叠摄像机视图中因视角变化导致的车辆匹配难题。针对现有方法直接从单一图像提取特征而缺乏视图不变性的问题,本文创新性地通过显式建模车辆组件间的结构关系来提升跨视角匹配性能。传统方法在比较不同方向车辆时存在明显局限,由于视角差异导致的遮挡使得判别性部件难以有效匹配。为此,本文设计了一个关键点驱动的框架:首先检测输入图像中的可见关键点,随后通过基于Transformer的模型,利用知识图中定义的部件关联关系来推理被遮挡关键点的特征表示。该方法的核心优势在于,即使某些部件因视角差异无法直接比较,仍能通过结构先验实现可靠匹配。具体实现包含三个关键步骤:(1)对查询图像和图库图像进行可见关键点检测;(2)依据知识图的结构关系,通过Transformer模型推断不可见关键点的特征;(3)综合可见与推理特征生成最终表示。实验结果表明,在标准跨视图匹配基准测试中,本方法显著优于现有最优算法。这是首次将关键点知识图的结构先验引入车辆重识别领域,为视图不变性匹配提供了新思路。
论文网址: https://ojs.aaai.org/index.php/AAAI/article/view/32630
代码网址: https://github.com/ilvkai/Knowledge-Graph-for-Vehicle-ReID
论文6
CoDe: Communication Delay-Tolerant Multi-Agent Collaboration via Dual Alignment of Intent and Timeliness
录用\发表平台:AAAI 2025
作者:Shoucheng Song, Youfang Lin, Sheng Han, Chang Yao, Hao Wu, Shuo Wang, Kai Lv
论文简介:
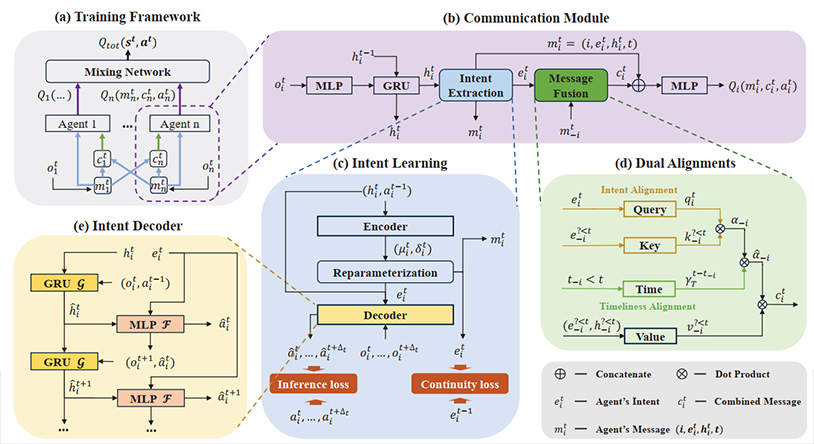
通信已被广泛用于增强多智能体协作。现有研究通常假设无延迟通信,这是一个在实践中难以实现的强烈假设。然而,现实世界中的代理会受到信道延迟的影响,接收在不同时间点发送的消息,称为异步通信,导致认知偏差和协作中断。本文首先定义了MARL中的两种通信延迟设置,并强调了它们对协作的危害。为了处理上述延迟,本文提出了一种新的通信延迟容忍多代理协作(CoDe)框架。首先,CoDe通过未来动作推理将意图表示作为消息学习,反映了代理未来稳定的行为趋势。然后,CoDe设计了一种意图和及时性的双重对齐机制,以加强异步消息的融合过程。通过这种方式,代理可以提取他人的长期意图,即使是从延迟的消息中,并有选择地利用与他们的意图相关的最新消息。实验结果表明,CoDe在三个无延迟的MARL基准测试中优于基线算法,并在固定和时变延迟下表现出鲁棒性。
论文网址: https://ojs.aaai.org/index.php/AAAI/article/view/34497
代码网址: https://github.com/SCSong-BJTU/CoDe/tree/main
论文7
From General Relation Patterns to Task-Specific Decision-Making in Continual Multi-Agent Coordination
录用\发表平:台IJCAI 2025
作者:Chang Yao, Youfang Lin, Shoucheng Song, Hao Wu, Yuqing Ma, Shang Han, Kai Lv
论文简介:
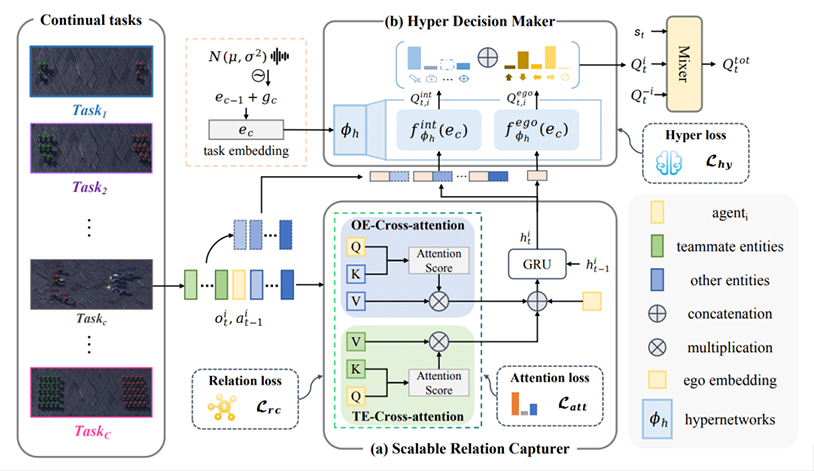
持续多智能体强化学习(Co-MARL)要求智能体在学习团队动态的新协作策略时解决灾难性遗忘问题。本文深入探究了Co-MARL的核心要素——关系模式(Relation Patterns),即智能体对交互关系的通用认知。除通用性外,当映射到不同动作空间时,关系模式还表现出任务特异性。为此,我们提出了一种名为"通用关系模式引导的任务特定决策器(RPG)"的新方法。在RPG框架中,智能体通过关系捕捉器从动态观察空间中提取关系模式,这些任务无关的关系模式随后通过条件超网络生成的任务特定决策器映射到不同动作空间。为克服遗忘问题,我们进一步在关系捕捉器和条件超网络上引入正则化项。在SMAC和LBF平台上的实验表明,RPG在学习新任务时能有效防止灾难性遗忘,并能实现对新任务的零样本泛化。
论文网址: https://arxiv.org/abs/2507.06004
代码网址: https://github.com/GeorgeYao123/RPG_IJCAI25
论文8
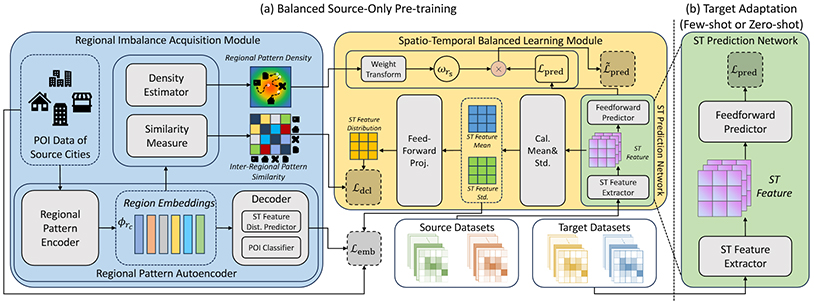
Balancing Imbalance: Data-Scarce Urban Flow Prediction via Spatio-Temporal Balanced Transfer Learning
录用\发表平台:IJCAI 2025
作者:Xinyan Hao, Huaiyu Wan, Shengnan Guo, Youfang Lin
论文简介:
基于深度时空网络的方法已经成为城市流量预测的主流方案,然而由于各城市发展差异及数据收集隐私等因素引起的城市可用数据稀缺现象普遍存在,阻碍了这些模型的广泛应用和部署。跨城市迁移学习技术有望成为解决这一问题的有效策略,但现有工作忽略了各城市内部固有的分布不平衡特性,潜在地降低了预训练模型的泛化能力。为此,本文提出了一种名为时空平衡迁移学习 (STBaT) 的新框架,以增强时空预测网络对于数据稀缺的新城市环境的通用性和准确性。STBaT首先通过不平衡获取技术来建模源城市的区域不平衡特性并生成指示信息,之后利用时空平衡学习技术来平衡预测学习的预训练过程,以促进可泛化的知识迁移。在多个真实的城市流量数据集上进行的广泛实验证实,本文提出的STBaT具有相比其他先进的跨城市迁移学习基线方法更优越的泛化性和准确性。
代码网址: https://github.com/ShaunHao/stbat
论文9
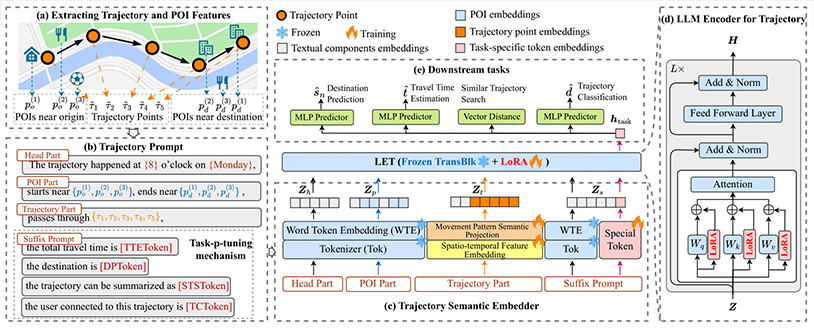
TrajCogn: Leveraging LLMs for Cognizing Movement Patterns and Travel Purposes from Trajectories
录用\发表平台:IJCAI 2025
作者:Zeyu Zhou, Yan Lin, Haomin Wen, Shengnan Guo, Jilin Hu, Youfang Lin and Huaiyu Wan
论文简介:
时空轨迹在数据挖掘任务中至关重要,这类任务需要能够准确提取运动模式和旅行意图的多任务学习方法。大语言模型(LLM)因其在大规模数据集上的出色表现,被广泛应用于多种任务。然而,标准LLM在处理包含丰富时空特征和运动语义的轨迹数据时,面临着难以直接建模和提取轨迹特有信息的挑战。为此,我们提出了TrajCogn,一种能够有效适配LLMs进行轨迹学习的模型。TrajCogn引入了一种新颖的轨迹语义嵌入器,从轨迹点原始特征的变化中提取运动模式,并从起终点附近兴趣点的功能语义建模旅行意图,同时设计了轨迹提示,将这些信息整合到LLM中,以支持各种下游任务。TrajCogn冻结大模型编码层,仅通过LoRA引入少量可学习参数,结合交叉重构预训练任务显著提升了模型对轨迹数据的建模能力。实验结果表明,TrajCogn不仅显著提升了轨迹学习任务的准确性和泛化性,也为大语言模型在时空轨迹领域的应用提供了新思路。
论文网址: https://arxiv.org/abs/2405.12459
代码网址: https://github.com/Zeru19/TrajCogn
论文10
From Pixels to Temporal Correlations: Learning Informative Representations for Reinforcement Learning Pre-training
录用\发表平台:ACM MM 2025
作者:Jinwen Wang, Youfang Lin, Xiaobo Hu, Siyu Yang, Sheng Han, Shuo Wang, Kai Lv
论文简介:
在大规模数据集上进行无监督预训练已被证明在提升强化学习 (RL) 的样本效率和性能方面具有巨大潜力。针对大规模无动作网络视频,现有方法利用单步转移预测和图像重建来学习表征。然而,这些方法倾向于在像素空间中保留大像素比例的平稳信息,而忽略了小占比但至关重要的信息。在对于下游任务没有先验的前提下,为了在表征中保留足够的信息,必须对视频中的每个元素给予同等的关注。具体而言,我们提出了一个时间相关性空间来区分每个元素。在实现上,我们设计了一组对比学习目标,分别对每个时间相关性尺度进行独立建模。这种方法可以平衡不同元素的注意力,并产生更具信息量的表征,从而有效地支持各种下游任务中的策略学习。在三个不同的下游基准(DMControl Remastered、Meta-World 和 CARLA)上进行了广泛的实验,证明了我们的方法显著提高了各种下游任务的样本效率和渐进性能。
代码网址: https://github.com/Wjw124/MSTC

论文11
Epipolar Consistency-based Network for Structure-Aware LF Semantic Segmentation
录用\发表平台:ACM MM 2025
作者:Chen Gao,Youfang Lin, Wenbin Wang and Shuo Zhang
论文简介:
光场语义分割旨在充分利用跨视角捕获的冗余信息,为中心视角中的每个像素分配精确的语义标签。现有主流方法通常将多个视图分别输入预训练的语义分割网络,并依赖估计的深度图来聚合多视角语义特征以细化标签预测。然而,这些方法存在两方面局限:一方面,语义分割网络往往更关注高层语义特征,忽略了细节信息,导致预测边界模糊、精度下降;另一方面,光场中记录的多视角语义特征存在高度冗余,直接融合不仅增加了无效计算,也带来了资源浪费。为解决上述问题,我们提出了一种基于极线一致性的结构感知光场语义分割网络,探索光场中结构线索与语义标签之间的相关性。首先,我们利用视图间的极线一致性来提取遮挡边缘和深度线索,作为指导信息。基于嵌入的遮挡边缘特征,我们设计了边缘-语义关联 Transformer,用于生成物体边缘的细粒度表示;同时,提出的深度-语义关联 Transformer 能将语义特征更紧密地映射到空间上相邻的位置,从而增强空间一致性与结构感知能力。实验结果表明,所提出的方法在显著降低计算复杂度的同时,能够实现最先进的分割性能,特别在细节还原和边界准确性方面表现出明显优势。

论文12
MoCERNet: A Modality-Complete Modeling Framework for Emotion Recognition in Physiological Signals under Imperfect Modal Matching
录用\发表平台:ACM MM 2025
作者:Tianzuo Xin, Jing Wang, Xiyuan Jin, Xiaojun Ning, Zhiyang Feng, Youfang Lin
论文简介:
基于多模态生理信号的情感识别在人机交互、疾病诊断等领域扮演着日益重要的角色,其可以很好地模拟人类情绪的复杂生理过程,且不易受到主观偏见或故意欺骗的影响,在情感计算研究中得到了广泛应用。然而,当前研究主要是在统一的数据采集范式下进行,忽视了现实场景中普遍存在的模态不完美匹配问题。尤其值得注意的是,现有方法未能有效利用这些不匹配模态,导致情绪表征不完整,这限制了模型准确捕捉多维情感语义特征的能力,进而制约了其在实际场景中的有效性和适用性。同时,现有方法忽略了不同脑区和外周生理信号间有价值的局部功能结构。针对上述挑战,本研究提出了一种名为MoCERNet的模型:采用多级分步对齐策略,使目标域和源域互相适应不匹配的模态范式组合,首先在模态层面缩小匹配模态间的差距,随后以匹配模态为指导,通过语义感知方式对齐不匹配模态;在决策层面,进一步消除全局差异以获得完整且具有泛化能力的表征。此外,我们设计了神经系统功能结构Transformer(NFSformer)使模型能聚焦于不同情绪状态下大脑各区域与外周生理信号间的关联性,从而增强其对复杂情绪过程的建模能力。在三个数据集上的结果表明,MoCERNet优于多个基准模型。我们希望我们的工作可以拓宽基于生理信号的情感识别模型的应用场景,并促进情感识别模型的未来发展和推广。

论文13
Exploring View Consistency for Scene-Adaptive Low-Light Light Field Image Enhancement
录用\发表平台:ICCV 2025
作者:Shuo Zhang, Chen Gao, Youfang Lin
论文简介:
光场图像蕴含的固有结构信息使其在诸多应用中展现出重要价值。然而,低质量的光场图像,尤其是在低光环境下捕获的图像,会严重制约相关应用的性能。尽管已有大量算法被提出,但现有方法仍存在两个关键局限:其一,基于学习的光场低光增强方法通常针对特定光照条件设计,限制了其在真实多变场景下的泛化能力;其二,低光输入常伴有显著噪声,现有方法在增强过程中难以有效保持图像固有的视图一致性。针对上述挑战,我们提出了一种光照感知的低光恢复网络架构,首次通过端到端训练实现了动态变化照度下的图像恢复。具体而言,基于Retinex理论,我们设计了一种可嵌入的光照感知模块。该模块通过融合光场图像的全局与局部信息,实现了对场景光照的动态感知。此外,基于光场照度图的视图一致性特性,我们创新性地设计了一种自监督视图一致性损失函数,引入视角一致性约束,有效保证了恢复结果的结构完整性。在固定照度和动态照度下的实验中,本文方法的恢复效果相较于现有技术有了显著的提升。

论文14
Epipolar Consistent Attention Aggregation Network for Unsupervised Light Field Disparity Estimation
录用\发表平台:ICCV 2025
作者:Chen Gao, Youfang Lin, Shuo Zhang
论文简介:
视差估计是光场图像处理与分析的关键步骤,现有方法通常通过构建代价体的方式来捕获其所蕴含的场景深度信息。然而,构建代价体需在预设的最大视差范围内计算对应关系,这限制了其处理大视差场景的能力。不同于代价体方法,自注意力机制通过计算极线间的视差注意力来寻找匹配点。然而,将自注意力机制应用于光场图像的视差估计仍面临两个主要挑战:(1)视差尺度不一致性:光场各视图的基线长度(相对于中心视点)存在差异,导致视差注意力的相关尺度各不相同,使得不同视角的视差信息难以直接融合。(2)遮挡问题:场景遮挡关系在各视图中表现不同。若某视图中的匹配信息被遮挡,则需借助其他视图来探索该区域的视差信息。针对上述挑战,我们提出了一种无监督的极线一致注意力聚合网络。首先,基于一致性考量,我们设计了极线一致尺度归一化模块,对视差注意力图的视差尺度进行标准化处理。其次,深入挖掘视差注意力的内在属性及其相互关系,我们进一步提出了一致无遮挡聚合模块,用于感知并融合无遮挡区域的信息。在多个主流光场数据集上,尤其是在大基线场景下的实验表明,本文方法相较于现有技术的性能有显著的提升。

论文15
Optimal Information Retention for Time-Series Explanations
录用\发表平台:ICML 2025
作者:Jinghang Yue, Jing Wang, Lu Zhang, Shuo Zhang, Da Li, Zhaoyang Ma, Youfang Lin
论文简介:
解释时间序列数据的深度模型对于识别敏感领域的关键模式至关重要,如医疗保健和金融。然而,由于缺乏统一的优化准则,现有的解释方法往往存在解释冗余和不完整的问题,包括解释中包含不相关的模式或遗漏关键模式。为应对这一挑战,本文提出最优信息保留原则,其中条件互信息将最小化冗余和最大化完整性定义为优化目标。然后从理论上推导出相应的目标函数。作为一个实用的框架,提出了一个解释框架ORTE,通过学习二进制掩码来消除冗余信息,同时挖掘解释的时间模式。将离散映射过程解耦,以确保梯度传播的稳定性,同时利用对比学习实现解释模式通过掩码的精确过滤,从而实现低冗余和高完整度的权衡。在合成数据集和真实数据集上的大量定量和定性实验表明,与基线方法相比,所提出的原则显著提高了解释的准确性和完整性。

论文16
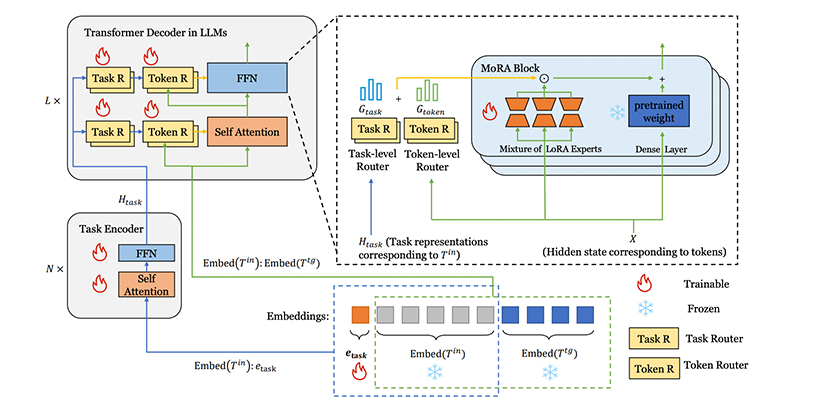
HMoRA: Making LLMs More Effective with Hierarchical Mixture of LoRA Experts
录用\发表平台:ICLR 2025
作者:Mengqi Liao, Wei Chen, Junfeng Shen, Shengnan Guo, Huaiyu Wan
论文简介:
最近的研究将专家混合 (MoE) 和参数高效微调 (PEFT) 相结合来微调大型语言模型 (LLM),在多任务场景中保持出色的性能,同时保持资源效率。然而,现有的 MoE 方法仍然存在以下局限性:(1) 当前的方法未能考虑到不同的 LLM 层以不同的粒度级别捕获特征,从而导致性能欠佳。(2) 现有的任务级路由方法缺乏对未曾见过的的任务的泛化性。(3) 负载均衡损失带来的不确定性破坏了专家的有效专业化。为了应对这些挑战,我们提出了 HMoRA,这是一种结合了 MoE 和 LoRA 的分层微调方法,采用混合路由,以分层方式集成令牌级和任务级路由。这种分层混合路由使模型能够更有效地捕获细粒度的令牌信息和更广泛的任务上下文。为了提高专家选择的确定性,引入了一种新的路由辅助损失。此辅助损失还增强了 task router 区分任务的能力及其对看不见的任务的泛化。此外,还提出了几种可选的轻量级设计,以显著减少可训练参数的数量和计算成本。
论文网址: https://iclr.cc/virtual/2025/poster/28518
代码网址: https://github.com/LiaoMengqi/HMoRA
论文17
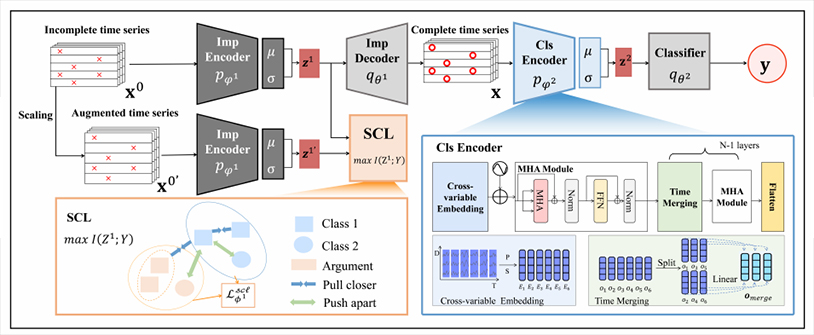
Loss or Gain: Hierarchical Conditional Information Bottleneck Approach for Incomplete Time Series Classification
录用\发表平台:KDD 2025
作者:Shuo Zhang, Jing Wang, Shiqin Nie, Jinghang Yue, Weikang Zhu, Youfang Lin
论文简介:
时间序列分类在医疗、工业监测等领域展现出广泛的应用价值。然而,实际场景中的数据缺失问题使得不完整时间序列分类研究更具实际意义与挑战性。传统的两阶段策略或单阶段联合建模方法存在两个关键局限性:第一,过度强调缺失值插补的数据重构一致性,忽视填充结果对分类任务的有效性;第二,未能系统建立数据插补与特征表示之间的协同优化机制。 针对上述挑战,本研究提出层次条件信息瓶颈框架(HCIB),通过端到端联合优化实现不完整时间序列分类。具体来说,在数据插补层面,我们重新审视了数据缺失的双重影响:在损失关键信息(Loss)的同时抑制信息干扰(Gain),并基于偏差-方差理论阐释这种双重影响的机理,在此基础上提出任务信息充分性准则,创新性地引入标签信息条件约束机制,将标准信息瓶颈理论扩展为任务(监督)驱动的填充框架;在特征表示层面,构建层次化信息瓶颈架构,在插补后的任务导向数据上学习紧凑且信息丰富的时序表征。在多领域多变量与单变量时间序列数据集进行的实验一致表明,本方法相较现有技术展现出显著的分类性能提升。
论文18
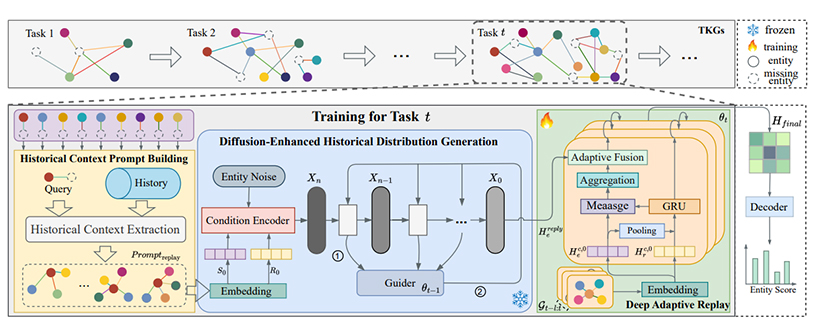
A Generative Adaptive Replay Continual Learning Model for Temporal Knowledge Graph Reasoning
录用\发表平台:ACL2025
作者:Zhiyu Zhang, Wei Chen, Youfang Lin, Huaiyu Wan
论文简介:
近期基于持续学习 (CL) 的时态知识图谱推理 (TKGR) 方法致力于大幅降低计算成本并减轻因使用新数据微调模型而导致的灾难性遗忘。然而,现有的基于 CL 的 TKGR 方法仍然存在两个关键限制:(1)它们通常片面地重新组织个别历史事实,而忽略了准确理解这些事实的历史语义所必需的历史背景;(2)它们通过简单地重放历史事实来保存历史知识,而忽略了历史事实与新兴事实之间的潜在冲突。在本文中,我们提出了一种 Deep Generative Adaptive Replay (DGAR) 方法,该方法可以从整个历史背景中生成并自适应地重放历史实体分布表示。为了解决第一个挑战,构建历史背景提示作为采样单元以保留整个历史背景信息。为了克服第二个挑战,我们采用预训练的扩散模型来生成历史分布。在生成过程中,我们在TKGR模型的指导下增强了历史分布和当前分布之间的共同特征。此外,我们还设计了一种逐层自适应重放机制,有效地融合了历史分布和当前分布。实验结果表明,DGAR在推理和缓解遗忘方面的表现显著优于基线模型。
论文网址: https://arxiv.org/abs/2506.04083
代码网址: https://github.com/zyzhang11/DGAR
论文19
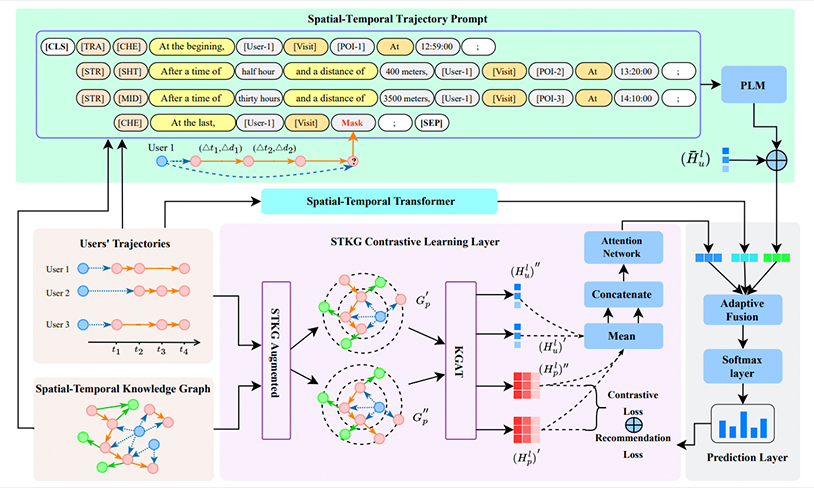
Next-POI Recommendation via Spatial-Temporal Knowledge Graph Contrastive Learning and Trajectory Prompt
录用\发表平台: IEEE TKDE 2025
作者:Wei Chen, Haoyu Huang, Zhiyu Zhang, Tianyi Wang, Youfang Lin, Liang Chang, Huaiyu Wan.
论文简介:
下一个兴趣点(POI)推荐旨在根据用户的历史签到轨迹预测其未来的移动,这在基于位置的服务中具有重要价值。现有的方法通过整合丰富的辅助信息或使用时空知识图谱来解决轨迹数据的稀疏性问题。然而,这些方法仍然面临两个主要挑战:i)由于将结构化的轨迹数据转换为描述用户时空移动性的轨迹文本存在困难,强大的预训练语言模型的推理能力很少被探索以提升推荐性能。ii)基于时空知识图谱的方法可能会引入与用户偏好不一致的外部知识,导致产生的知识噪声妨碍推荐的准确性。为此,本文提出了一种名为 STKG-PLM 的下一个POI推荐模型,该方法结合了时空知识图谱对比学习和提示预训练语言模型。在STKG-PLM中,设计了一种时空轨迹提示模板,该模板基于 STKG 将结构化轨迹转换为文本语料库,作为预训练语言模型的输入,从粗粒度和细粒度的角度理解用户的移动模式。此外,还提出了一种时空知识图谱对比学习框架,以减轻引入的知识噪声。在三个真实世界数据集上进行的大量实验表明,STKG-PLM 相较于最先进的基线方法表现出显著的性能提升。
论文网址: https://ieeexplore.ieee.org/document/10904285
代码网址: https://github.com/WeiChen3690/STKG-PLM
论文20
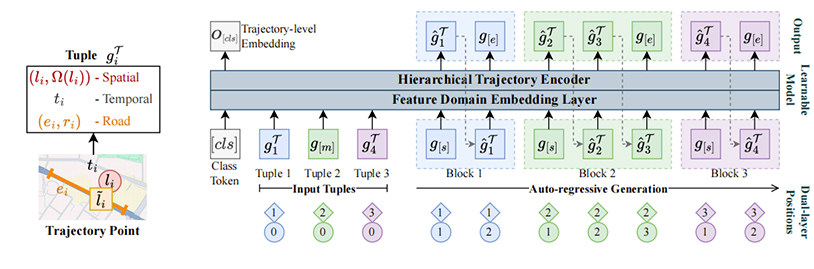
UVTM: Universal Vehicle Trajectory Modeling with ST Feature Domain Generation
录用\发表平台: IEEE TKDE 2025
作者:Yan Lin, Jilin Hu, Shengnan Guo, Bin Yang, Christian S. Jensen, Youfang Lin, Huaiyu Wan
论文简介:
车辆运动通常以GPS轨迹的形式被捕捉,即一系列带有时间戳的GPS位置点。此类数据被广泛应用于多种任务,如行程时间估计、轨迹恢复和轨迹预测。一个通用的车辆轨迹模型可以应用于不同任务,从而减少维护多个专用模型的需求,降低计算和存储成本。然而,当轨迹特征的完整性受到损害时(例如,仅部分特征可用或轨迹稀疏),构建这样的模型具有挑战性。为了解决这些问题,本文提出了通用车辆轨迹模型(UVTM),它能够有效适应不同任务而无需大量重新训练。UVTM包含两个专门设计:首先,它将轨迹特征划分为三个独立的域,每个域可以独立掩码和生成,以处理部分特征可用的任务;其次,UVTM通过从稀疏、特征不完整的轨迹中重建密集、特征完整的轨迹进行预训练,即使在轨迹特征完整性受损的情况下也能保持强大的性能。在三个真实世界车辆轨迹数据集上的四项代表性任务的实验表明,UVTM能够实现其设计目标。
论文网址: https://ieeexplore.ieee.org/abstract/document/11004614/
代码网址: https://github.com/Logan-Lin/UVTM.
论文21
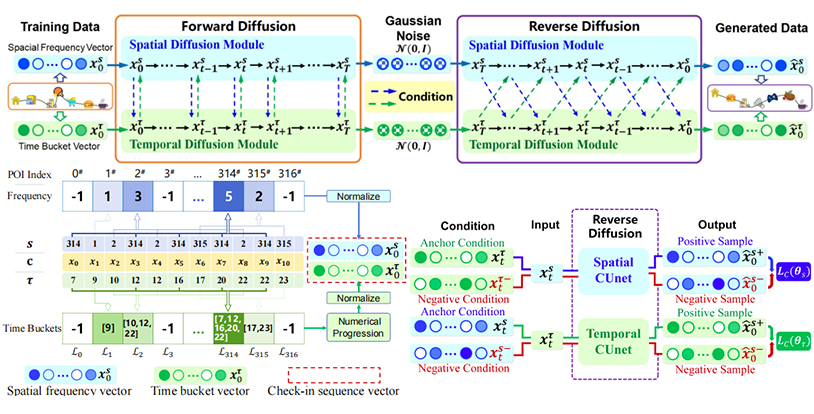
STCDM: Spatio-Temporal Contrastive Diffusion Model for Check-in Sequence Generation
录用\发表平台: IEEE TKDE 2025
作者:Letian Gong, Shengnan Guo, Yan Lin, Yichen Liu, Erwen Zheng, Yiwei Shuang, Youfang Lin, Jilin Hu, Huaiyu Wan
论文简介:
随着智慧城市的发展,如何安全、高质量地模拟用户的移动签到行为,已成为城市计算、出行推荐与隐私保护研究中的核心问题。我们团队近期提出的 STCDM 模型,为“真实无泄露”的人类移动数据生成开辟了全新路径。本研究聚焦于“签到序列合成数据生成”,即在人类时空行为存在隐私敏感性且真实数据稀缺的前提下,如何模拟出既真实又无泄露风险的签到数据。 在多个真实数据集上的实验显示,STCDM 在多个指标上全面优于现有最先进方法。可视化结果也表明其在签到时间与空间分布的模拟能力更接近真实数据。 研究团队指出,STCDM 的提出不仅提升了生成模型在城市签到序列上的表现,也为构建“安全、开放、真实”的大规模人类移动合成数据集提供了方法论基础,未来可广泛应用于出行模拟、交通仿真、个性推荐、社会行为建模等领域。
论文网址: https://ieeexplore.ieee.org/abstract/document/10836764
代码网址: https://github.com/LetianGong/STCDM
论文22
UniTE: A Survey and Unified Pipeline for Pre-training Spatio-temporal Trajectory Embeddings
录用\发表平台: IEEE TKDE 2025
作者:Yan Lin, Zeyu Zhou, Yicheng Liu, Haochen Lv, Haomin Wen, Tianyi Li, Yushuai Li, Christian S. Jensen, Shengnan Guo, Youfang Lin, Huaiyu Wan
论文简介:
针对轨迹数据挖掘领域长期存在的技术分散、评估标准不统一等难题,研究团队首次系统梳理了20余种预训练方法,并提出模块化统一框架UniTE。该框架通过五大核心组件实现"即插即用"式开发,开源代码库支持交通预测、物流路径规划等多场景应用,实验显示其能将下游任务性能最高提升47%。 UniTE框架已成功应用于智慧交通与物流管理领域,物流企业应用后路径规划效率提升18%。GitHub开源项目上线即获300+星标,成为轨迹分析领域的热门工具。UniTE为时空人工智能研究提供了标准化解决方案,未来将扩展对多模态轨迹的支持能力。这一成果标志着我国在时空数据智能领域取得重要技术突破,为城市治理和交通优化提供了新范式。
论文网址: https://ieeexplore.ieee.org/abstract/document/10818577
代码网址: https://github.com/Logan-Lin/UniTE.
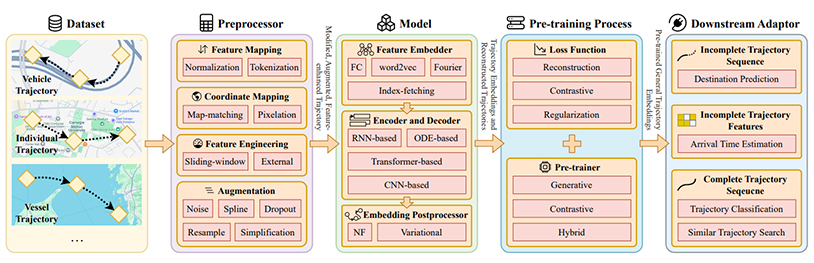
论文23
Progressive Multi-Plane Images Construction for Light Field Occlusion Removal
录用\发表平台:TVCG 2025
作者:Shuo Zhang, Song Chang, Zhuoyu Shi, Youfang Lin
论文简介:
因为光场包含了场景的多个视角图像,使得在某些视角中被遮挡的物体在其他视角中可能可见,因而在去除前景遮挡方面,尤其是离散分布的遮挡物(如栏杆、铁丝网、树木和草丛等),展现出巨大潜力。然而,现有的基于光场的方法隐式地对场景进行建模,且仅能去除单一中心视图中具有正视差的遮挡物。本文提出了一种专为光场遮挡去除设计的渐进式多平面图像(Multi-Plane Images, MPI)构建方法。与先前MPI构建方法不同,我们采用从近到远的顺序逐层渐进构建MPI,将较近层中前景遮挡物的位置作为遮挡先验精确建模当前层。具体而言,我们提出一种遮挡感知注意力网络(Occlusion-Aware Attention Network),通过遮挡区域的可靠信息生成每一层MPI。对于每一层,当前层的遮挡物被滤除,从而仅利用可见视角(而非其他被遮挡视角)更好地恢复背景。通过简单移除含遮挡物的层级并从多视角渲染MPI,即可生成不同视角的遮挡去除结果。在合成和真实场景上的实验表明,该方法在定量指标和视觉效果上均优于当前最先进的光场去遮挡方法。此外,我们还将所提出的渐进式MPI构建方法应用于视图合成任务。合成结果中遮挡边缘的质量显著提升,进一步验证了我们的方法能更好地建模被遮挡区域。
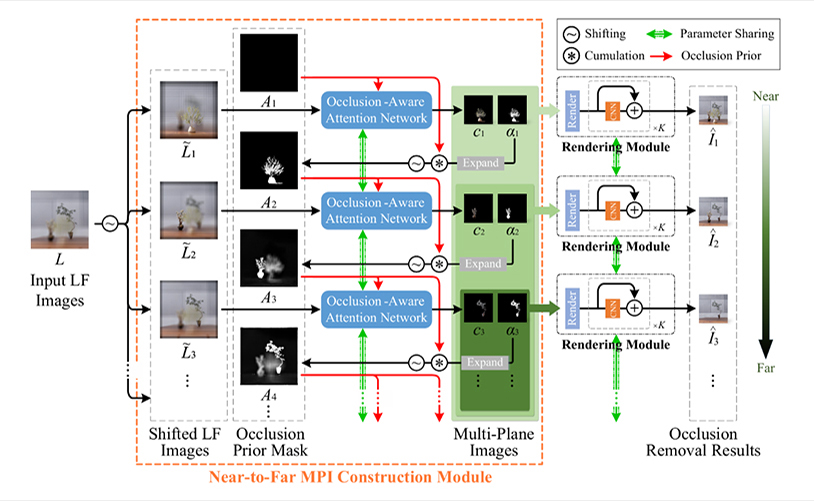
论文24
A Comprehensive Study of OOP-Related Bugs in C++ Compilers
录用/发表平台: IEEE TSE 2025
作者:Bo Wang, Chong Chen, Junjie Chen, Bowen Xu, Chen Ye, Youfang Lin, Guoliang Dong, Jun Sun
论文简介:
现代 C++ 作为一种高度依赖OOP特性的编程语言,广泛应用于系统编程领域。然而,C++ 编译器在处理复杂的 OOP 特性时常常表现不佳,导致出现大量影响较大的编译器缺陷,甚至引发崩溃或错误编译。尽管 OOP 相关的缺陷具有重要影响,现有研究却普遍忽视了对 OOP 特性的系统性分析,限制了此类缺陷的发现与防范。为此,本文面向编译器模糊测试工具设计者与编译器开发者,系统性地开展了针对 C++ OOP 特性引发的编译器缺陷的实证研究。首先,作者从 GCC 与 LLVM 中系统提取了 788 个 OOP 相关的 C++ 编译器缺陷;其次,基于 OOP 与 C++ 的核心概念,人工构建了包含 6 个一级分类(如抽象与封装、继承、运行时多态)及 17 个二级分类(如构造与析构、多重继承)的两级特性分类体系;第三,作者对这些缺陷的根因、表现、修复方式、触发选项及对应的 C++ 标准版本进行了系统分析,并总结出 13 条关键发现,如对象构造与析构相关的特性引发的缺陷最多,崩溃是最常见的表现形式,缺陷从引入到被发现平均需时 1856 天,但一旦发现后平均修复时间仅需 174 天,且超过一半的缺陷无需任何编译选项即可触发。这些发现不仅为新型编译器测试方法的研究提供了依据,也对语言设计与编译器工程有重要启发。受此启发,作者开发了面向 OOP 特性缺陷的原型编译器模糊测试工具 OOPFuzz,并在 GCC 和 LLVM 的最新版本上进行了实验,3 小时内成功检测出 9 个缺陷,其中 3 个已被官方确认,包括一个潜伏 13 年的 LLVM 缺陷。实验结果表明,本文提出的特性分类与分析为未来编译器测试研究提供了有价值的参考。
论文网址: https://www.computer.org/csdl/journal/ts/2025/06/10985855/26trl5iYMww

论文25
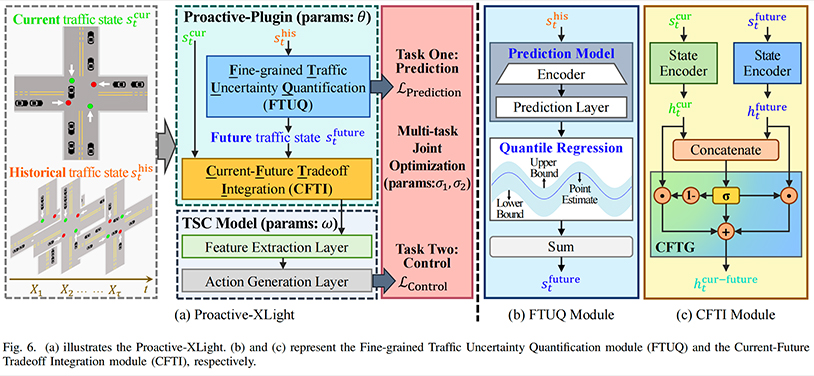
Proactive-XLight: Proactive Traffic Signal Control With Pluggable and Reliable Traffic Prediction
录用\发表平台:IEEE TMC 2025
作者:Yang Jiang, Shengnan Guo*, Hanyang Chen, Xiaowei Mao, Youfang Lin, and Huaiyu Wan
论文简介:
交通信号控制(Traffic Signal Control,简称TSC)在智能交通系统中发挥着至关重要的作用。在现有的TSC方法中,主动式交通信号控制(Proactive Traffic Signal Control,简称PTSC)通过预测交叉口的未来交通状态,主动调整控制策略。已有研究表明,PTSC方法在缓解当前和未来交通拥堵方面具有显著效果。然而,现有的PTSC方法主要依赖点估计预测,忽视了预测结果的可靠性。此外,这些方法也未能在当前与未来交通状态之间实现自适应协调,从而影响控制效果。为了解决上述问题,本文提出了一种创新性的Proactive-Plugin,该插件可以与现有TSC方法结合使用,从而提升交通信号控制策略的准确性与鲁棒性。该插件主要增强了两方面关键能力:1)预测可靠性增强:通过细粒度级交通不确定性量化(Fine-grained Traffic Uncertainty Quantification)模块,生成带置信区间的概率分布预测结果,明确表达预测结果的可信程度;2)协调自适应性增强:通过当前-未来权衡融合机制(Current-Future Tradeoff Integration),动态调整当前交通状态与概率预测结果对控制策略的影响权重。此外,为进一步增强鲁棒性,本文设计了多任务联合优化机制(multi-task joint optimization),在训练过程中降低预测误差带来的负面影响。基于六个真实世界数据集的实验结果表明,该方法在提升交通效率方面具有显著的优势,有效验证了本文方法的实用性和有效性。
论文网址: https://ieeexplore.ieee.org/abstract/document/11045885
代码网址: https://github.com/YangJiangDev/Proactive-XLight