研究所动态
我所三篇文章被计算语言学领域国际会议ACL录用
发布时间:2026年4月10日
近日,ACL 2026公布录用结果,由我所师生共同完成的3篇论文被大会录用,其中1篇论文被ACL主会录用,2篇被Findings of ACL录用。ACL会议是计算语言学领域最重要的国际会议,是CCF推荐的计算语言学方面唯一的A类会议。本次ACL 2026一共有12148篇投稿,主会录用率为19%,Findings录用率为18%。论文的相关信息如下:
论文一
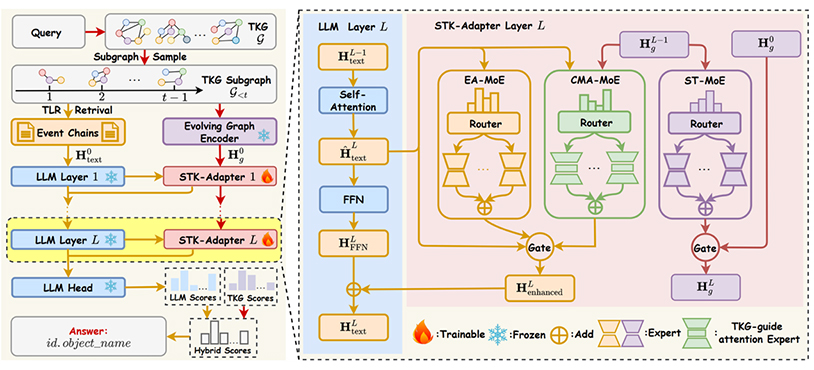
STK-Adapter: Incorporating Evolving Graph and Event Chain for Temporal Knowledge Graph Extrapolation
Accepted by ACL 2026 Main Conference
论文主要由我所博士生赵书源、已毕业博士陈炜(现桂林电子科技大学讲师)、硕士生张伟杰、侯昕蕊、沈俊锋、史博彦,在郭晟楠、林友芳、万怀宇三位老师的指导下完成。
时序知识图谱(TKG)外推旨在基于历史事实预测未来事件。近期的研究尝试将 TKG 的演化结构表示与文本事件链整合到大语言模型(LLM)中以提升推理能力,但面临图演化结构表示与 LLM 语义空间对齐不足以及结构特征在LLM微调过程中被逐渐稀释的问题。为此,研究团队提出时空知识适配器(STK-Adapter),通过将演化图编码器与 LLM 灵活整合以促进 TKG 推理。具体而言,设计时空混合专家模块以建模 TKG 的空间结构与时间演化模式;引入事件感知混合专家模块以捕捉事件链中的时间语义依赖;同时构建跨模态对齐混合专家模块,通过 TKG 引导的注意力机制实现深层跨模态对齐。在多个基准数据集上的实验结果表明,STK-Adapter 显著优于现有最先进方法,并在跨数据集场景中展现出良好的泛化能力。
论文二
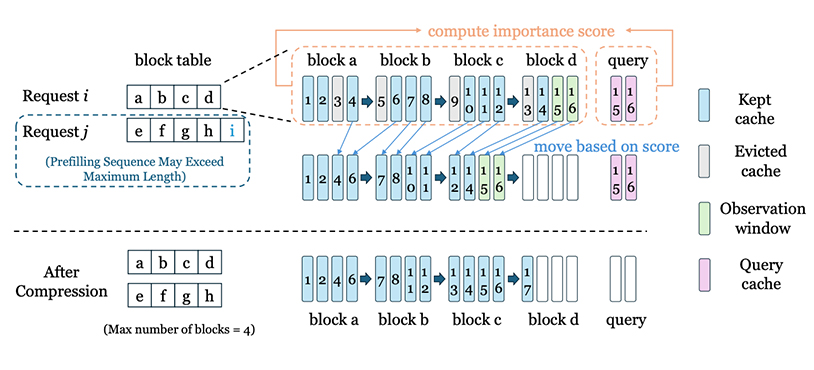
Zipage: Maintain High Request Concurrency for LLM Reasoning through Compressed PagedAttention
Accepted by Findings of ACL 2026
论文由我所硕士生廖梦祈、万怀宇老师与微软研究院相关研究人员共同合作完成。
随着推理逐渐成为大型语言模型(LLM)的生成范式,解码阶段由 KV 缓存(KV cache)引起的内存瓶颈已成为限制高并发服务的关键因素。尽管现有的 KV 缓存淘汰(eviction)方法能够在一定程度上解决内存问题,但其中大多数在工业级应用中并不实用。本文介绍了一种名为 Compressed PagedAttention 的方法,该方法将逐 Token(token-wise)的 KV 缓存淘汰机制与 PagedAttention 结合了起来。研究团队提出了一套综合的调度策略,并为 Compressed PagedAttention 提供了前缀缓存(prefix caching)和异步压缩的支持。基于此,我们开发了一款高并发的 LLM 推理引擎——Zipage。在大规模数学推理任务中,Zipage 达到了完整 KV(Full KV)推理引擎约 95% 的性能,同时实现了超过 2.1 倍的速度提升。
论文三
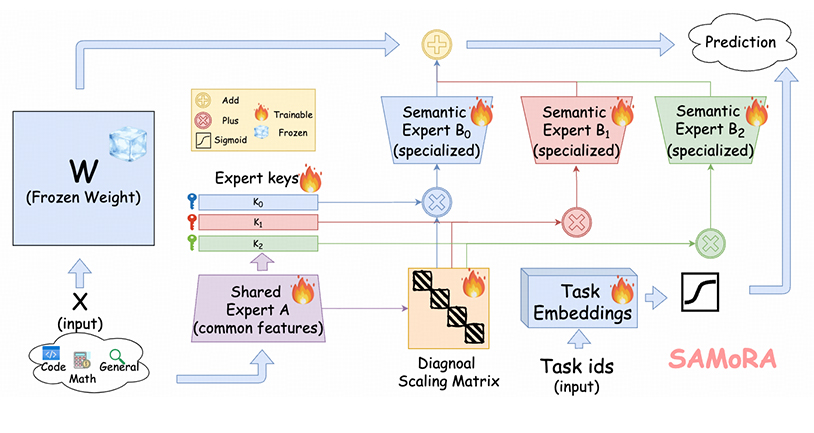
SAMoRA: Semantic-Aware Mixture of LoRA Experts
Accepted by Findings of ACL 2026
论文由我所硕士生史博彦、陈炜(桂林电子科技大学讲师)、博士生赵书源、万怀宇老师和中科院工业人工智能研究所王少将老师共同合作完成。
大型语言模型(LLM)的多任务学习是人工智能与自然语言处理领域的重要研究方向,而混合专家架构(MoE)与低秩微调(LoRA)的结合在提升模型多任务学习能力方面展现出了巨大的潜力。然而,现有的 MoE-LoRA 方法面临两大挑战:一是“路由不精准(Imprecise Routing)”,无法将输入语义与专家能力进行显式匹配,导致专家专业化程度较弱;二是“统一的权重融合策略(Uniform weight fusion)”难以提供自适应的更新强度,忽略了不同任务在复杂度上的显著差异。针对上述问题,研究团队提出了一种专为任务自适应学习量身定制的新型参数高效微调(PEFT)框架——SAMoRA(基于语义感知的混合 LoRA 专家模型)。该方法提出了一种语义感知路由器(Semantic-Aware Router),将文本语义与最合适的专家进行显式对齐,从而实现精准路由。同时,研究团队设计了任务自适应缩放机制(Task-Adaptive Scaling),能够根据特定的任务需求动态调节专家的贡献度。此外,该工作还引入了一种新颖的正则化目标,协同促进专家专业化与有效的自适应缩放。实验结果表明,SAMoRA 在多个多任务学习基准测试中均显著优于现有最先进(SOTA)的方法,并展现出了卓越的任务泛化能力。